PENG9570 — Lecture 4 (February 27th)
Two-dimensional dynamical systems
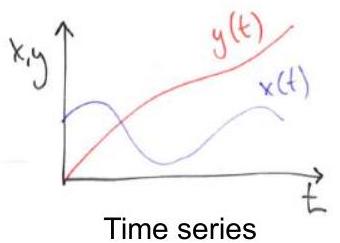
Solution: — functions of time.
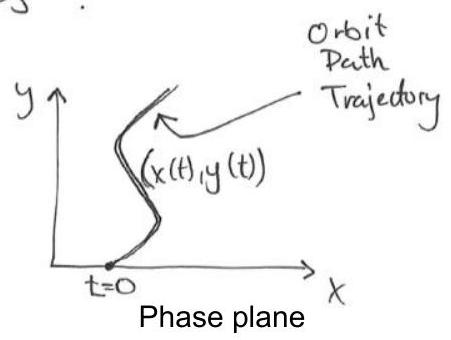
Solution curves:
Linear systems
, where is the coefficient matrix. The dynamics can be deduced from the eigenvalues and eigenvectors of .
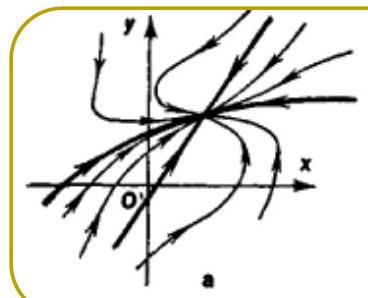
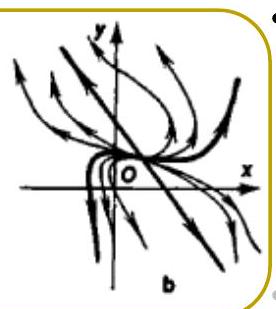
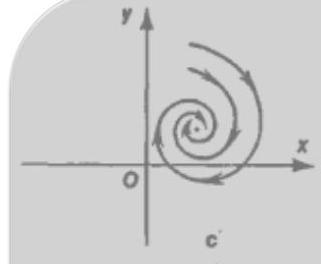
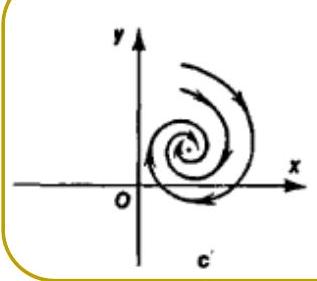
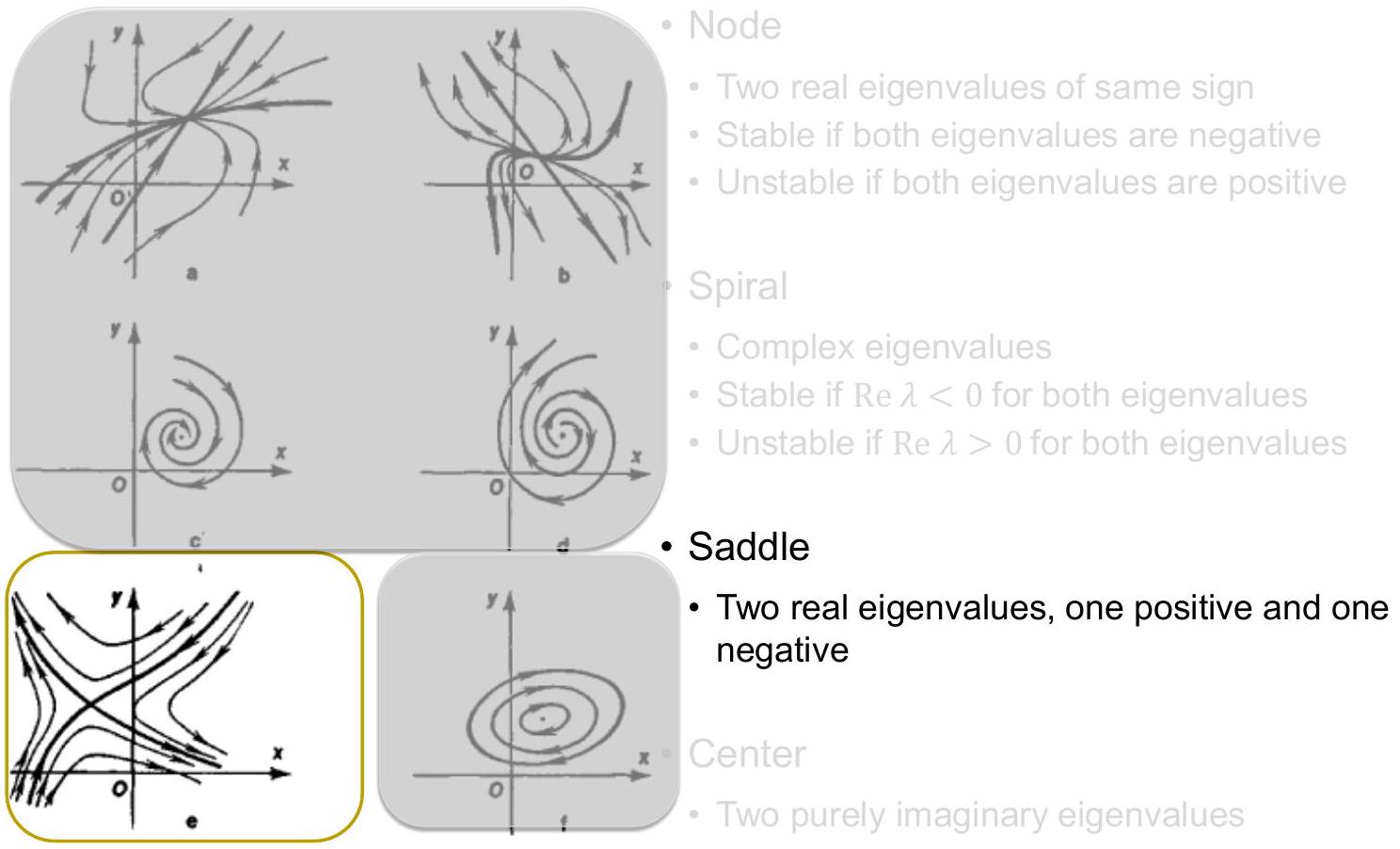
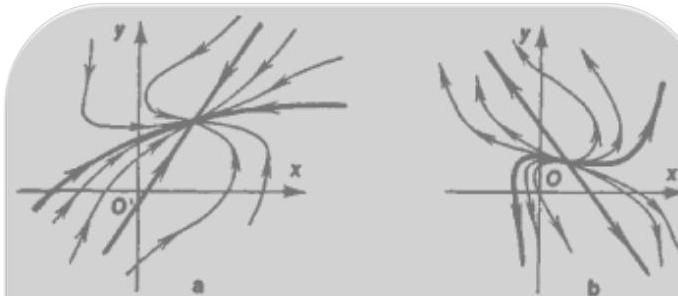
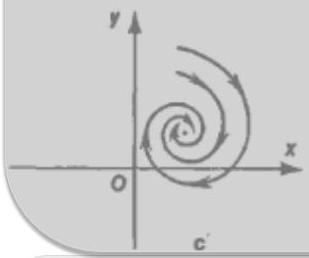
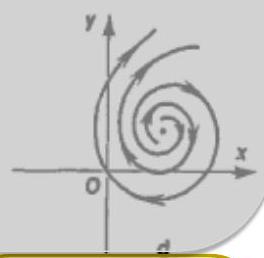
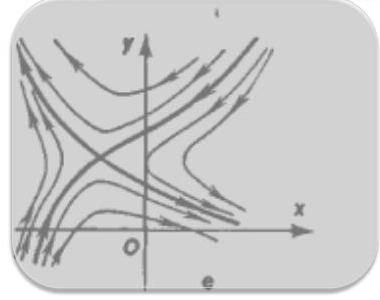
Classification of equilibria
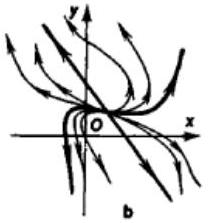
- Node — two real eigenvalues of the same sign.
- Stable if both eigenvalues are negative.
- Unstable if both eigenvalues are positive.
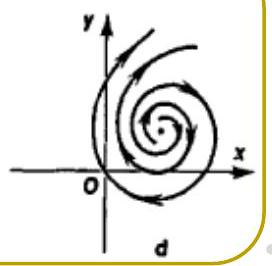
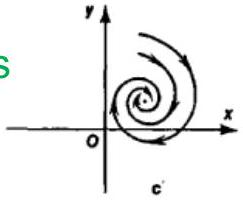
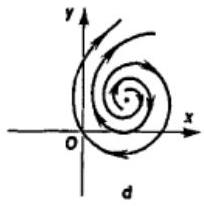
- Spiral — complex eigenvalues.
- Stable if for both eigenvalues.
- Unstable if for both eigenvalues.
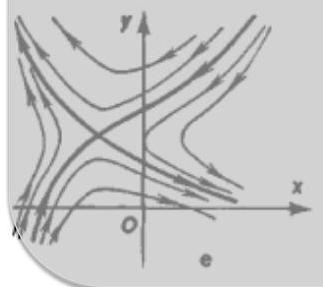
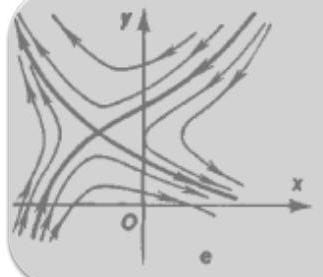
- Saddle — two real eigenvalues, one positive and one negative.
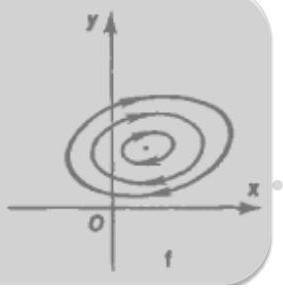
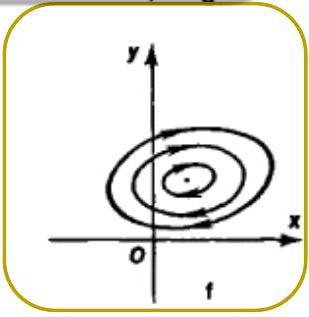
- Center — two purely imaginary eigenvalues.
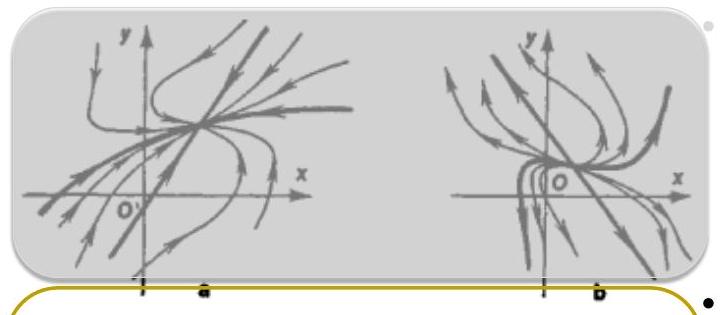
General solutions of linear ODE systems
Case 1: Two real, unequal eigenvalues with corresponding eigenvectors and :
Case 2: One real eigenvalue (skipped)
Case 3: Complex conjugate eigenvalues with corresponding eigenvectors :
System linearised around the origin
Assumption: equilibrium in .
Linearisation: (due to
is the Jacobian.
Dynamics can be deduced from eigenvalues and eigenvectors of Jacobian
The Hartman-Grobman theorem


Jacobian
Assume that are eigenvalues of the Jacobian: a. If the eigenvalues and are not equal real numbers or are not pure imaginary numbers, then the trajectories of the almost linear system (7.3.2) near the equilibrium point behave the same way as the trajectories of the associated linear system (7.3.3) near the origin. That is, we can use the appropriate table entries given in Section 6.9 to determine whether the origin is a node, a saddle point, or a spiral point of both systems. d. If and are complex conjugates with a nonzero real part, then the origin is unstable or asymptotically stable, depending on whether the real part of is positive or negative, respectively. e. If and are pure imaginary numbers-that is, , then the origin is a center for the linearized system, but may not be a center for the nonlinear system. The origin is either a center or a spiral point of the nonlinear system. Also, this spiral point may be asymptotically stable, stable, or unstable, depending on the nonlinear terms neglected during the linearization.
The Hartman–Grobman theorem
Nonlinear linear? Yes:

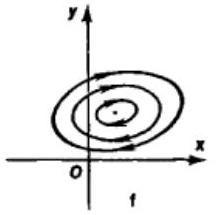
Nonlinear linear? Not necessarily (the ambiguous case of purely imaginary eigenvalues).
Nullclines
Example:
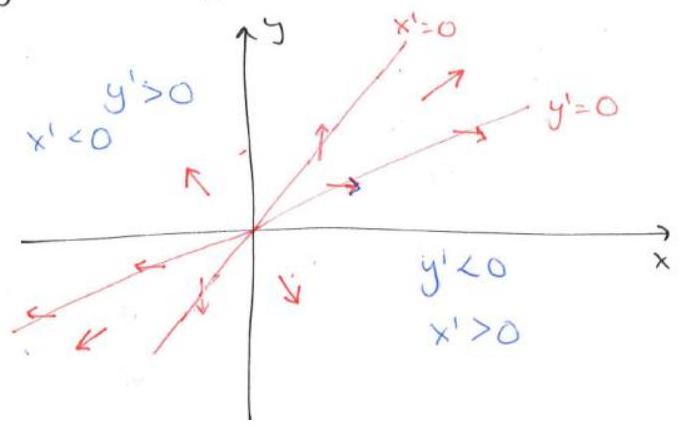
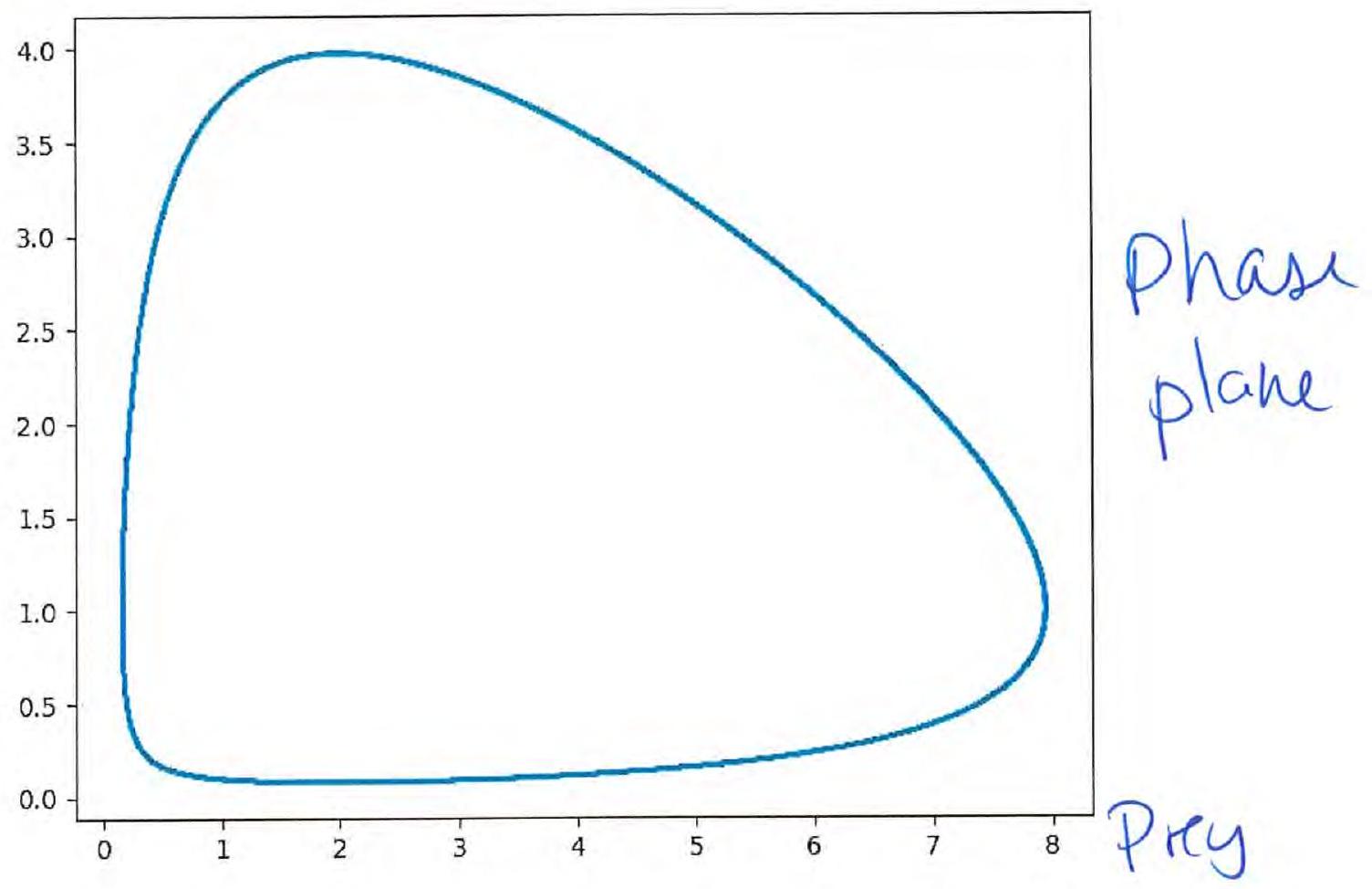
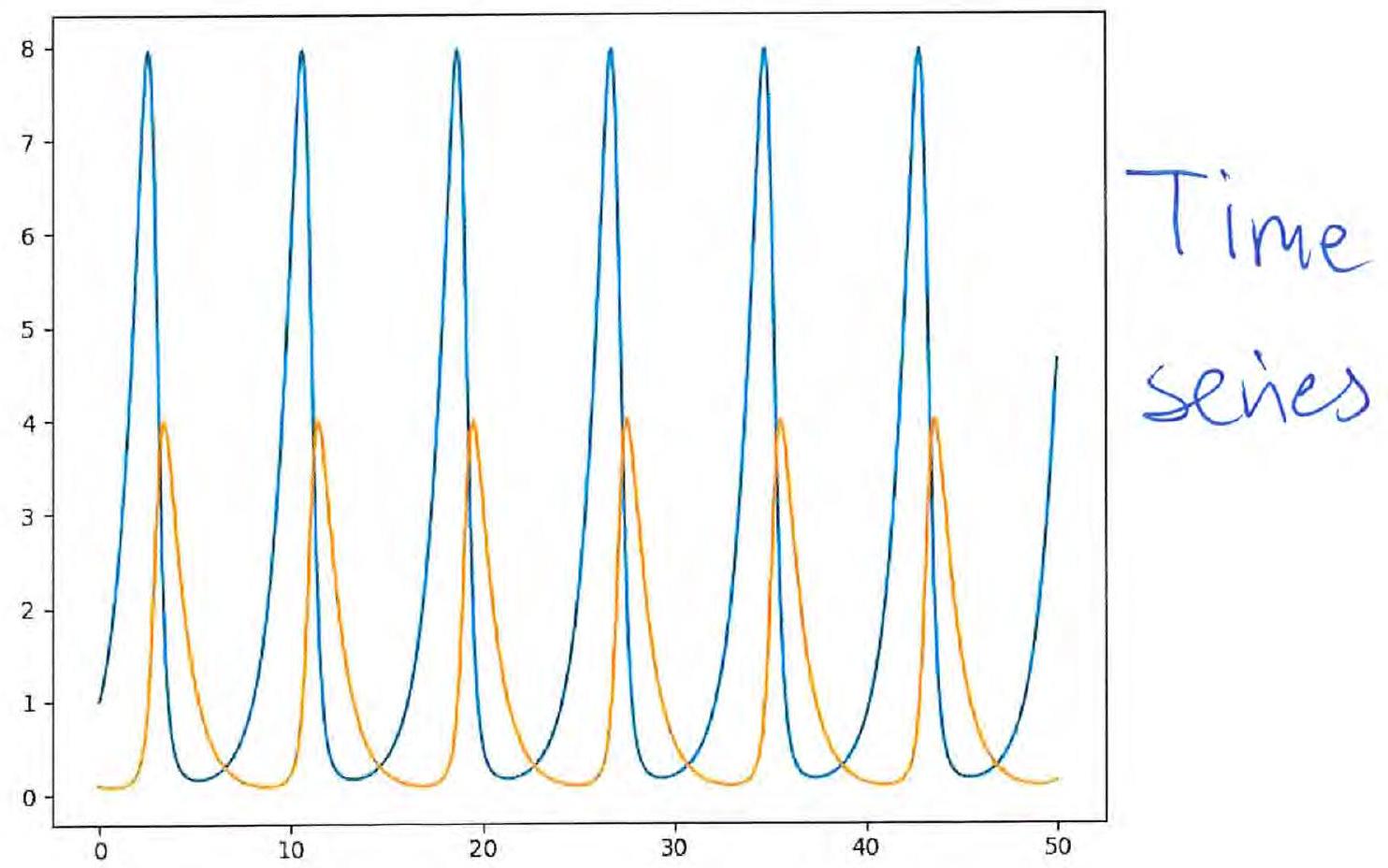
Problem – Sketch nullclines of the Lotka-Volterra equations
Identify equilibria and their type.
The Lotka–Volterra equations
Prey–predator interactions:
- : prey population size
- : predator population size
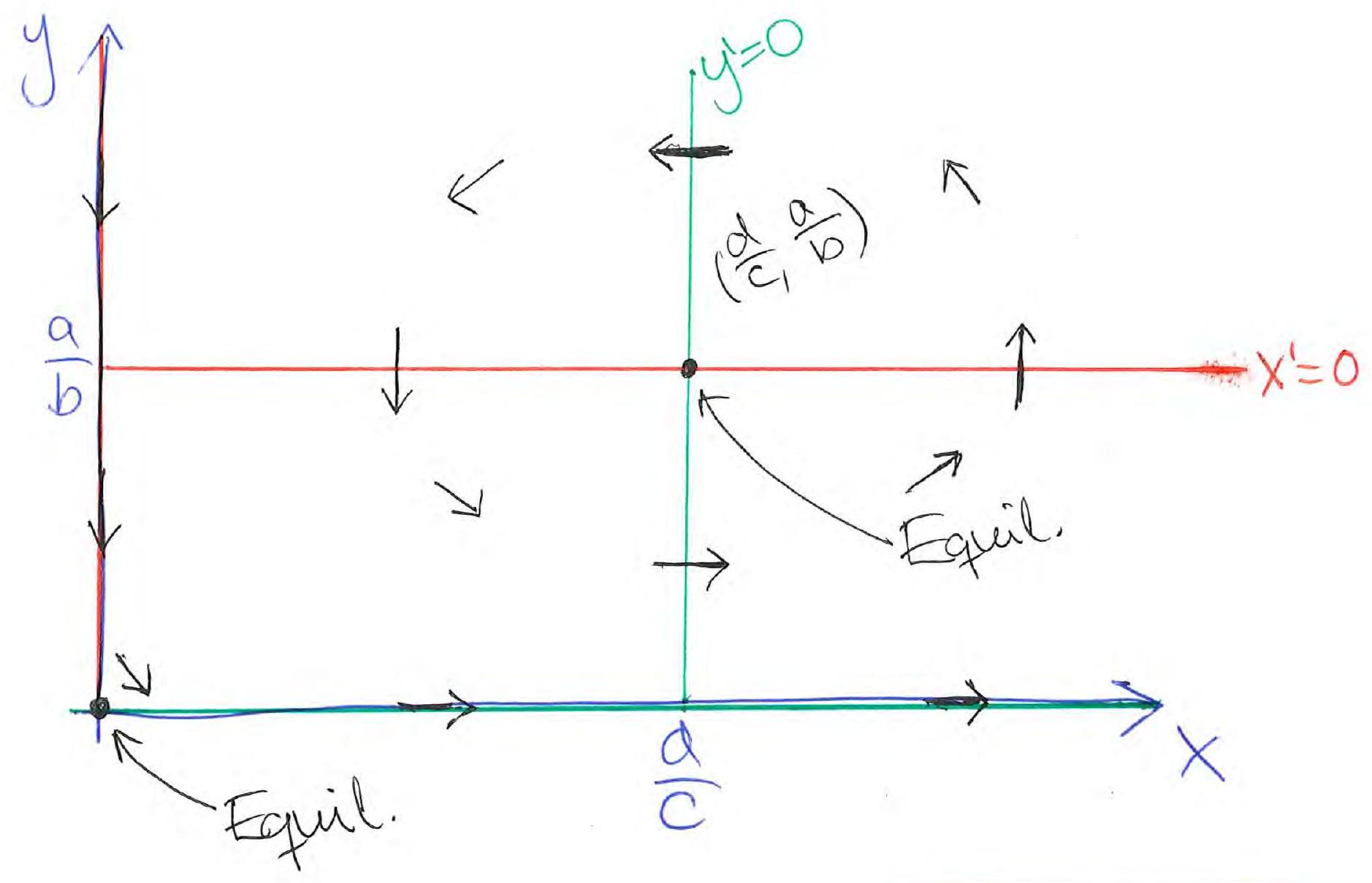
Nullclines:
Jacobian:
Jacobian in :
This is a diagonal matrix with eigenvalues and , so is a saddle.
Jacobian in :
Eigenvalues:
Purely imaginary eigenvalues: a center (in the linearised system). Based on the Hartman-Grobman theorem we cannot conclude whether the nonlinear system has a center — but in fact it does.
The undamped pendulum
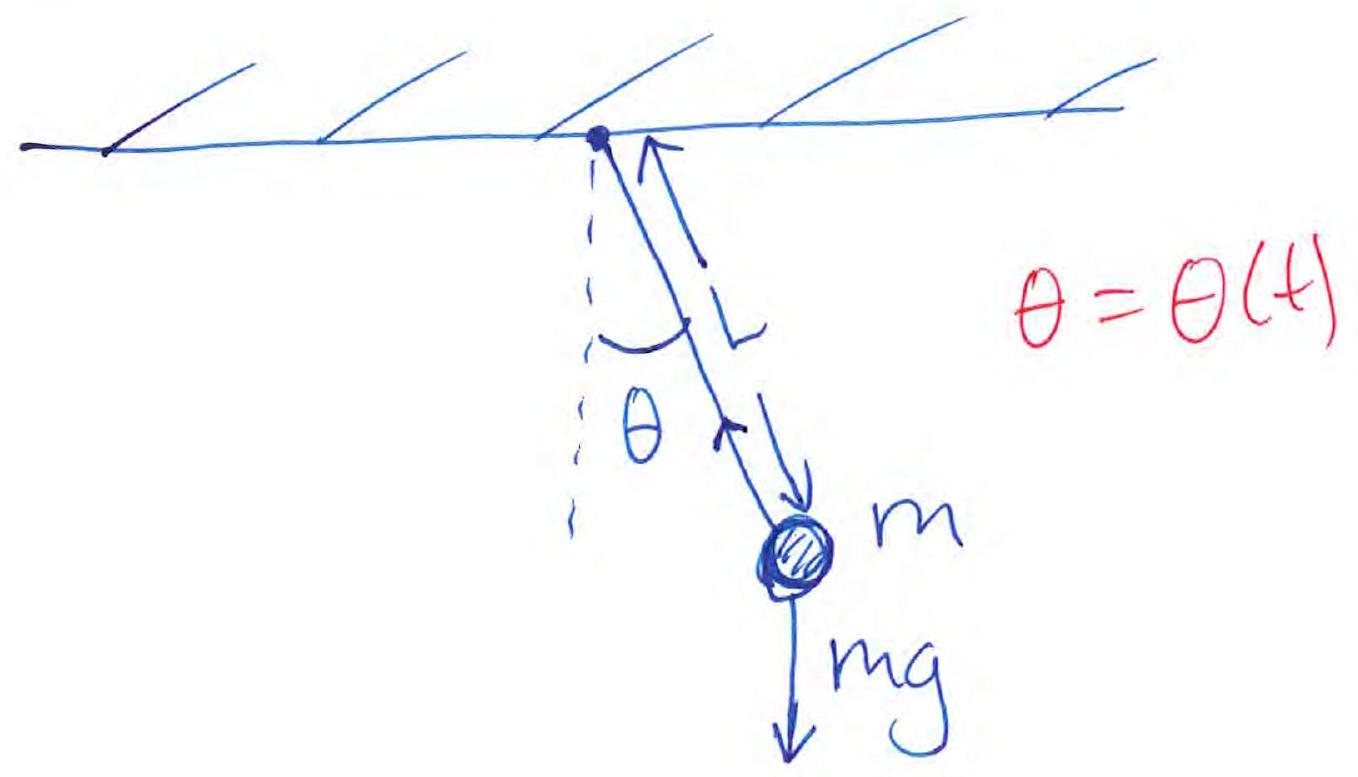
Newton’s 2nd law gives
Introduce , such that
Equilibria: (from ) and (from ).
Linearised system near : when , so the linearised system is
I ask the question in the bullets
- Why is this the linearization?
- Bc the nullclines (equilibria?)
No, it is not because of the nullclines. This is the linearization because of the first-order Taylor series approximation (or small-angle approximation) of the nonlinear function near the equilibrium point .
Why this is the linearization:
The original nonlinear system for the undamped pendulum is:
Near the equilibrium point , is very close to (). The Taylor series expansion of around is:
For values of close to , the higher-order terms (like ) are extremely small and can be neglected. This yields the linear approximation:
Substituting this back into the original system yields the linearized system:
Verification via the Jacobian Matrix:
As shown in the section on systems linearized around the origin, you can also find this using the Jacobian matrix at :
Evaluating these partial derivatives at yields:
Multiplying this matrix by gives the exact same linearized equations.
Jacobian:
Eigenvalues:
Purely imaginary eigenvalues. is a center in the linearised system.
Nullclines:
- when
- when
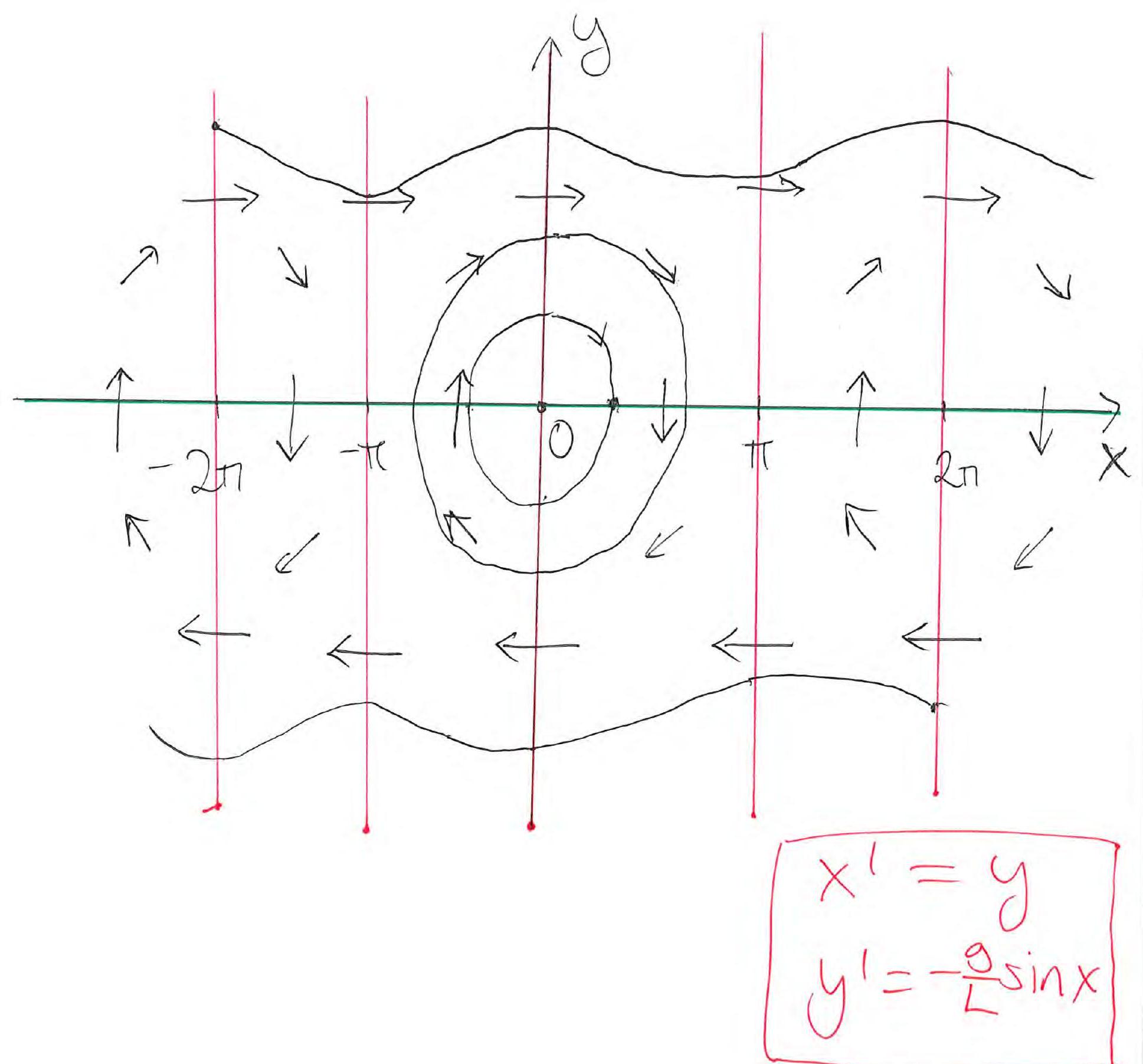
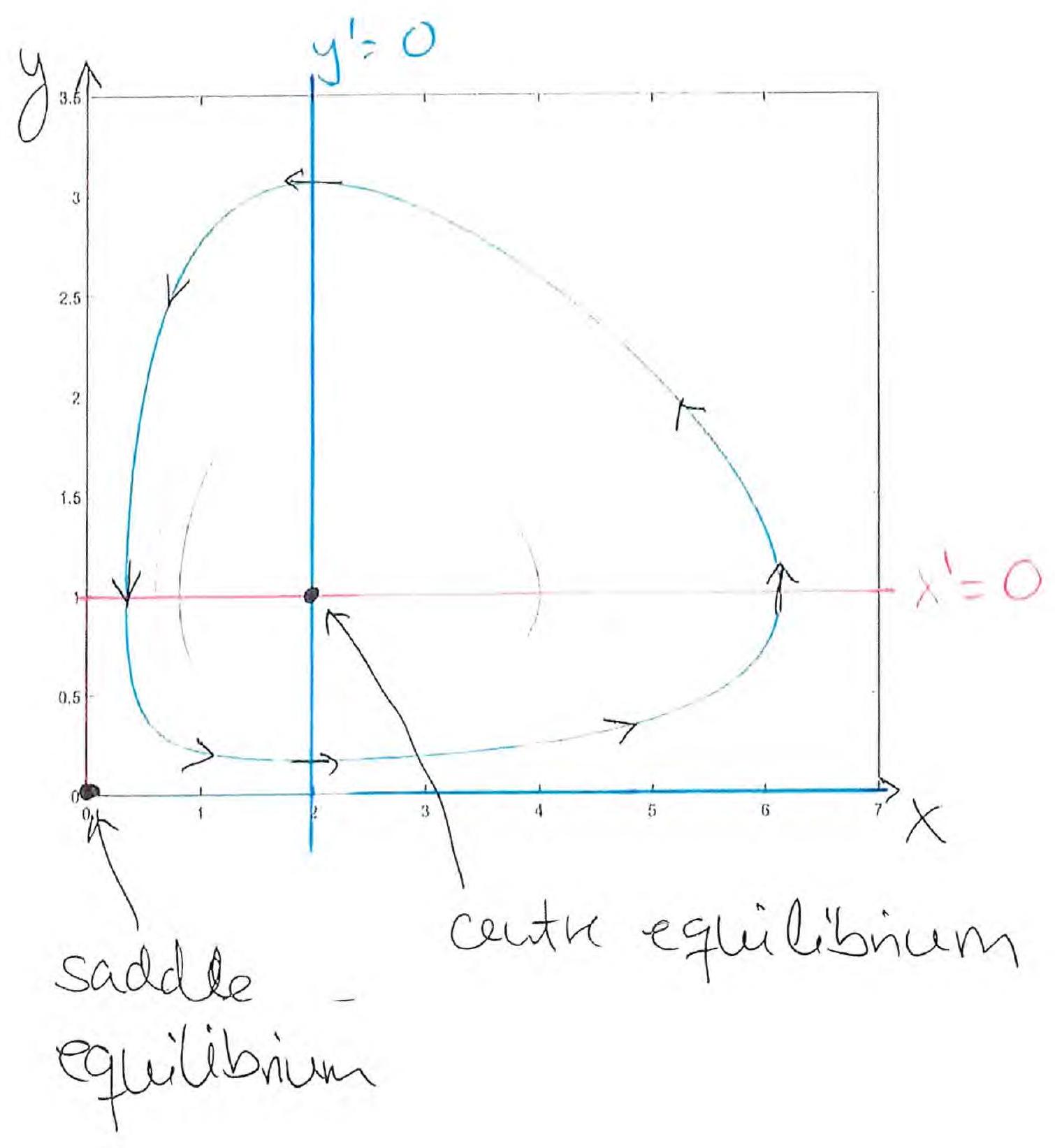
Solution curves of the undamped pendulum model
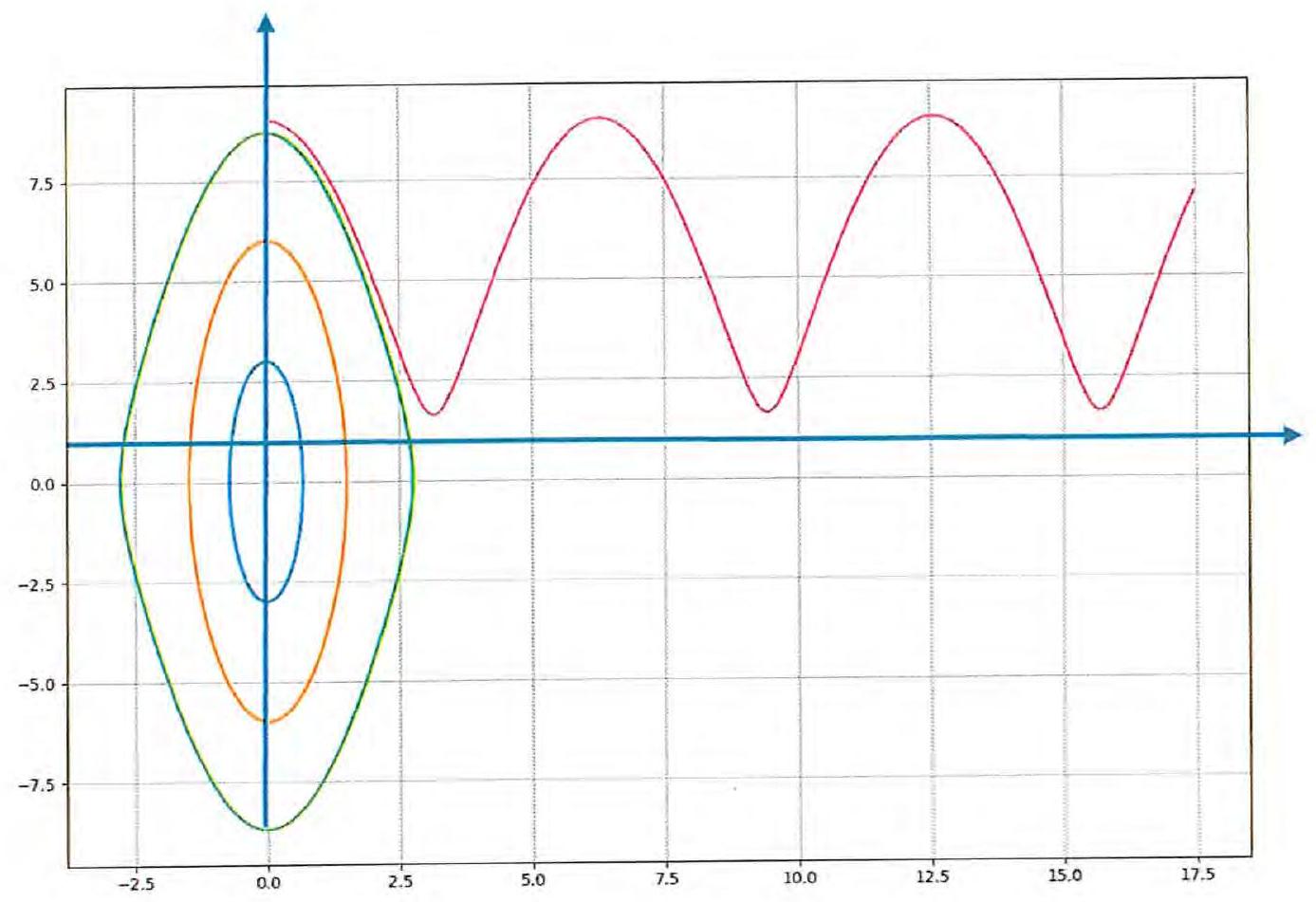
- Blue:
- Yellow:
- Green:
- Red: — the pendulum continues around and around for eternity.
Numerical solution of initial value problems (IVPs)
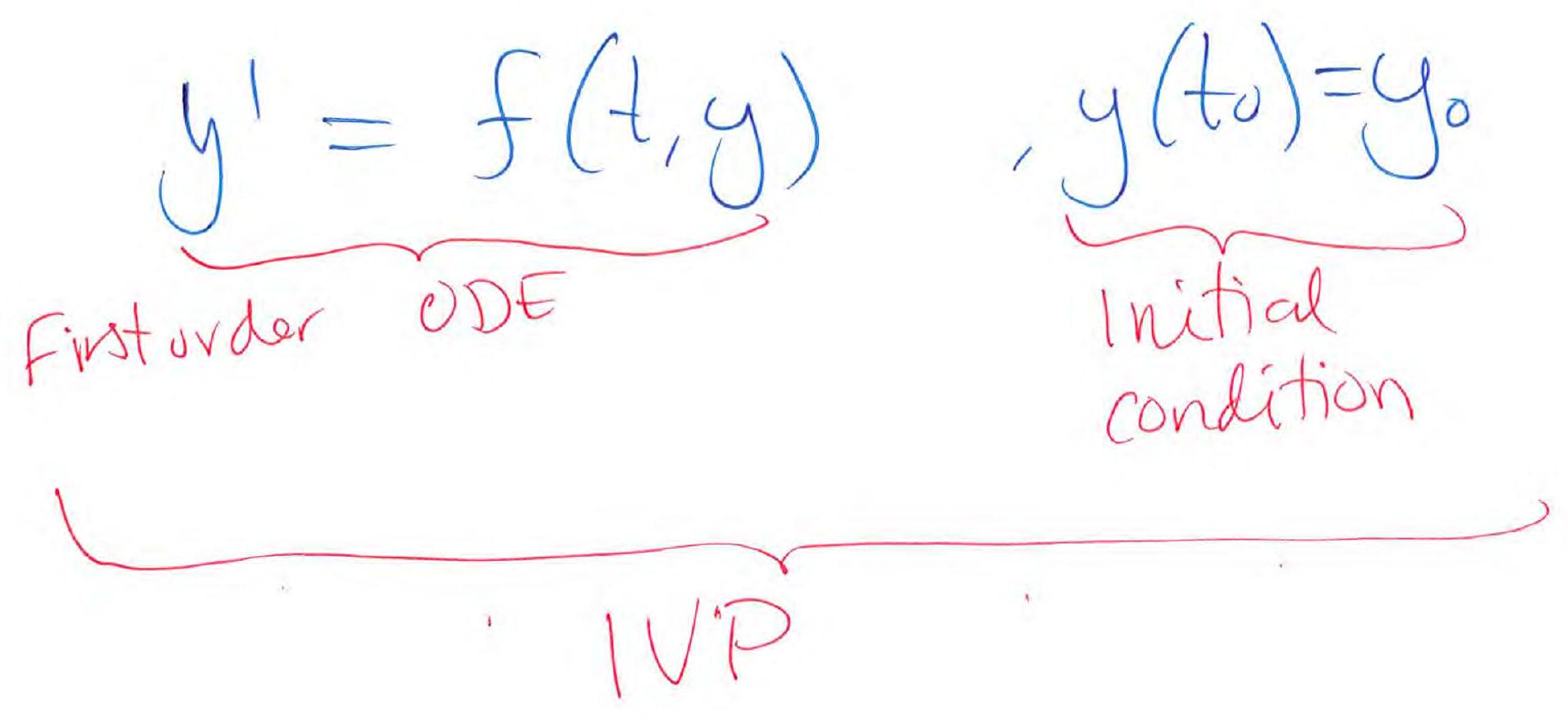 IVP:
First order ode:
Initial condition:
IVP:
First order ode:
Initial condition:
Generally, numerical methods are needed to solve IVPs.
Euler’s method
What does "h" represent here? I assume the time difference in a "euler step". If so also explain Euler steps.
ROBOT GENERATED – gemini-3.5-flash
What Represents
Your assumption is correct. In Euler’s method, represents the step size (or time step), which is the constant time difference between consecutive grid points:
What is an “Euler Step”?
An Euler step is a single iteration of Euler’s method used to approximate the solution of an initial value problem (IVP) at the next discrete time point.
Instead of finding an exact analytical solution curve, you take small, discrete steps forward in time.
How it works:
- Linear Approximation: It assumes that the rate of change (slope) of the curve remains approximately constant over the short time interval .
- Tangent Line Projection: At any point where the solution value is , the slope of the solution curve is given by the differential equation:
- The Step Formula: To calculate the next value at , you move a distance along the tangent line:
By repeating this step-by-step calculation (e.g., calculating from , then from , and so on), you generate a sequence of approximations that reconstruct the solution curve over time.
Linearisation of at :
Sequence of approximations with :
Example
Exact solution: . Euler’s method:
We know that
How do we know this?
ROBOT GENERATED – gemini-3.5-flash
We know this because of the analytical solution to the given differential equation and basic limit properties:
The Exact Solution: The initial value problem is given in the note as: This is a first-order linear ordinary differential equation whose exact solution is:
The Limit: As approaches infinity (), the exponent approaches negative infinity (). Since the exponential function decays to as its exponent goes to :
Give me the exact steps of this analytical solution
ROBOT GENERATED – gemini-3.5-flash
To solve the first-order linear ordinary differential equation (ODE) given in the example:
we use the method of separation of variables. Here are the exact analytical steps:
Step 1: Write the equation in Leibniz notation
Express the derivative as :
Step 2: Separate the variables
Move all terms involving to the left side and all terms involving to the right side (assuming ):
Step 3: Integrate both sides
Integrate the left side with respect to and the right side with respect to :
where is the constant of integration.
Step 4: Solve for
Exponentiate both sides to eliminate the natural logarithm:
By defining a new constant , we can remove the absolute value:
Step 5: Apply the initial condition
Using the given initial condition , substitute and into the general solution to find :
Step 6: Write the final exact solution
Substitute back into the general solution:
Therefore we should have
For this to hold we need (the stability criterion)
Alternatively, use the implicit Euler method:
This gives:
regardless of the value of .
A little theory
Integrating the ODE from to :
Instead, integrate from to :
Given and This (above) is the basis for all “Runge–Kutta” methods.
Is there a mathematical difference between the nomenclatures y(j) and y_j ? Or is it just a change of notation?
ROBOT GENERATED – gemini-3.5-flash
Based on the provided note, there is a key conceptual and mathematical distinction between the two, even though the highlighted snippet transitions between them as a change of notation:
- represents the exact analytical solution to the differential equation evaluated at the specific time grid point .
- represents the numerical approximation of the solution at that time step.
This difference is explicitly defined earlier in the note during the introduction of Euler’s method:
“Sequence of approximations with “
Why the snippet equates them:
In the highlighted snippet:
This substitution is used as a notation change to transition the exact continuous equation into the discrete framework used by Runge-Kutta methods. Once this change is made, the remaining continuous integral is approximated numerically (e.g., using Riemann sums or Simpson’s rule) to compute the final step-by-step values for .
The integral is estimated using numerical integration.
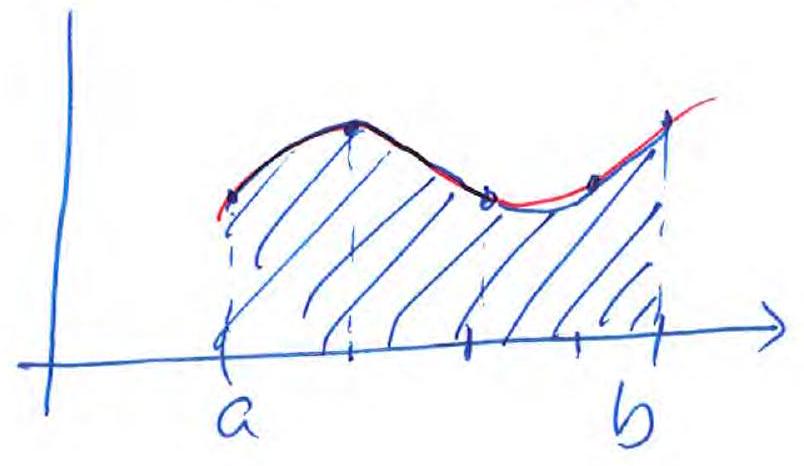
Left Riemann sum:
(same for the right Riemann sum)
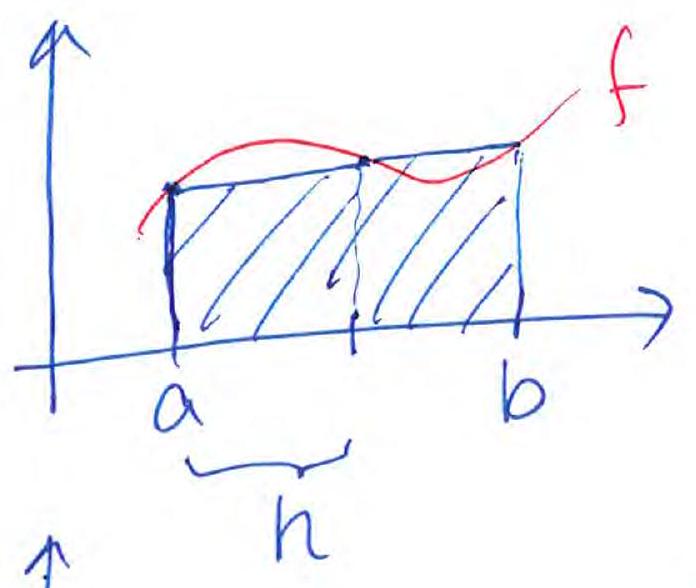
Mid-point rule:
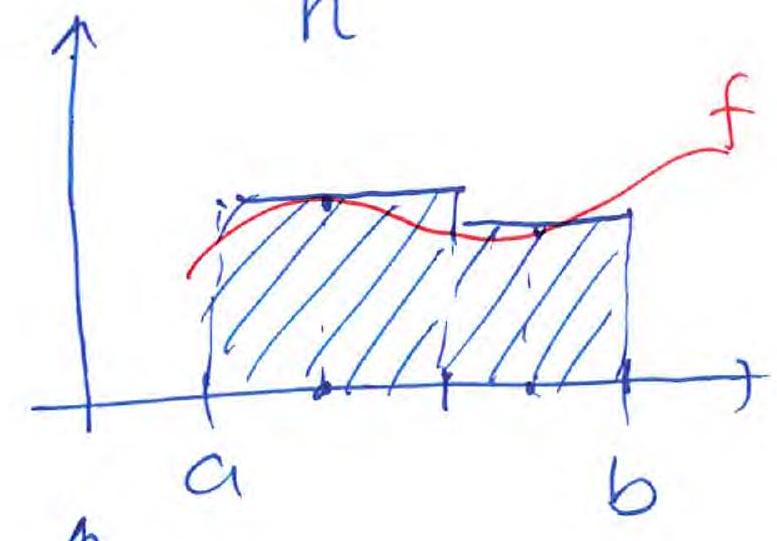
Trapezoidal rule:

Simpson’s rule:
Accuracy and “O”-notation
means(? Maybe not sure from slide) where is a constant independent of (might have been written “”).
What does the h, and N here represent? What is meant by "numerical estimate"?
ROBOT GENERATED – gemini-3.5-flash
Based on the provided note, the terms in the highlighted snippet represent the following:
1. What represents
represents the step size (or integration interval width). In the context of solving initial value problems numerically, it is the step size between successive grid points (i.e., ).
2. What represents
represents the order of accuracy (or rate of convergence) of the numerical approximation method.
- It determines how rapidly the error decreases as the step size is made smaller.
- For example, the left Riemann sum has (), whereas Simpson’s rule has ().
3. What is meant by “numerical estimate” ()
The “numerical estimate” is the approximated value of the actual continuous integral computed using a discrete numerical integration scheme.
Depending on the method chosen in the note, this estimate could be calculated using:
- A Riemann sum (used in Euler’s method)
- The Mid-point rule
- The Trapezoidal rule
- Simpson’s rule (used in the 4th order Runge–Kutta method)
Example: Riemann left sum
Using Taylor’s theorem, for some :
What happens here at the steps from the first integral to the second? It seems the integral is split apart, but how?
ROBOT GENERATED – gemini-3.5-flash
The transition between the first and second integral lines relies on two fundamental properties of integration: the linearity of integration and factoring out constants.
Here is the step-by-step breakdown of how the integral is split:
1. Linearity of Integration
The integral of a sum is equal to the sum of the integrals. We can split the integrand into two separate integrals:
Substituting this back into the first equation yields:
2. Factoring Out Constants
Since the integration is with respect to , any term that does not depend on acts as a constant and can be pulled outside the integral.
Here, is a fixed intermediate value in the interval , which means is a constant with respect to . Pulling it outside of its integral gives:
3. Rearranging the Terms
Putting it all together and rearranging the terms (moving the term to the middle) gives the second line exactly:
What is the symbol here correspond to?
ROBOT GENERATED – gemini-3.5-flash
The symbol in the highlighted snippet is actually ** (the lowercase Greek letter “xi”)**, rather than (sigma).
In this context (the Mean Value Theorem, which is a first-order case of Taylor’s Theorem), represents:
- An intermediate point strictly inside the open interval , meaning .
- The specific value at which the derivative is evaluated so that the Taylor approximation becomes an exact equality:
Mathematically, the theorem guarantees that there exists at least one such point where the instantaneous slope of the function (the tangent at ) is exactly equal to the average slope (the secant) over the interval .
The methods for solving IVPs
Explicit Euler (Euler’s method)
Implicit Euler
Implicit: additional methods are needed to solve the nonlinear equation at each timestep.
What does the "j" variable represent here. It doesn't appear to be the timestep.
ROBOT GENERATED – gemini-3.5-flash
The variable represents the step index (or iteration/grid index) in the discrete sequence of numerical approximations.
Here is how it relates to the other variables:
- (Step Index): An integer counter () representing the current step in the sequence.
- (Timestep / Step Size): The constant time increment between steps ().
- (Time at step ): The actual physical time value at the -th step, calculated as:
- (Numerical Approximation): The approximated value of the true solution at time (i.e., ).
In Euler’s method, incrementing from to means you are taking the next discrete step forward in time.
In plain language, what is the difference between the Explicit and Implicit methods?
ROBOT GENERATED – gemini-3.5-flash
Based on the provided note, the main differences between explicit and implicit methods are:
Explicit Methods (e.g., Explicit Euler): These methods calculate the next step () directly using only known information from the current step (). While they are straightforward to compute, they are only stable under specific step-size () constraints (e.g., the stability criterion shown in the note’s example).
Implicit Methods (e.g., Implicit Euler): These methods define the next step () in terms of itself, meaning the unknown variable appears on both sides of the equation: Because is embedded inside the function , you cannot calculate it directly. Instead, additional methods are needed to solve the nonlinear equation at each timestep. The benefit of this extra work is that implicit methods remain stable regardless of the chosen step size .
Runge–Kutta 2nd order — Heun’s method
is implicit?
Introduce the explicit-Euler estimate of :
Add more commentary about Heun's Method and what is happening in these steps
ROBOT GENERATED – gemini-3.5-flash
Understanding Heun’s Method (RK2)
Heun’s Method (also known as the Improved Euler Method) is a second-order Runge-Kutta method (RK2). It is designed to achieve higher accuracy than standard Euler’s method by treating the integration step as a Predictor-Corrector sequence.
Here is a step-by-step breakdown of what is happening in the highlighted snippet:
Step 1: Integrating with the Trapezoidal Rule
To advance the solution of the IVP from to , we integrate both sides:
Instead of approximating this integral using a flat rectangle (which yields the first-order Euler’s method), Heun’s method uses the Trapezoidal rule. This averages the slope at the beginning () and the end () of the step:
Step 2: The Implicit Dilemma ( is implicit?)
If we directly substitute the Trapezoidal rule into our integral equation, we get:
This equation is implicit because the unknown term we want to calculate, , appears on both the left-hand side and inside the function evaluation on the right-hand side. Normally, solving this would require root-finding iterations (like Newton’s method) at every single step, which is computationally expensive.
Step 3: The Predictor Step (Explicit Euler Estimate)
To bypass the implicit equation while keeping the accuracy benefits of the Trapezoidal rule, Heun’s method introduces a predictor.
We calculate a preliminary “prediction” of the next state, denoted as , using a simple, cheap explicit Euler step:
Step 4: The Corrector Step (The Final Heun Formula)
Now, we resolve the implicit bottleneck. We substitute our predicted value into the right-hand side of our Trapezoidal rule in place of the unknown :
- This is the corrector step.
- By evaluating the slope at the starting point and the predicted ending point , the algorithm takes an average of these two slopes to compute a far more accurate trajectory.
- Because the calculation is now entirely explicit, it is straightforward to compute. It improves the global error of the approximation to compared to the error of standard Euler’s method.
Mid-point method
(Mid-point rule, ). Introduce the explicit-Euler estimate of :
Add more commentary about the mid-point method and what is happening in these steps
ROBOT GENERATED – gemini-3.5-flash
Understanding the Mid-point Method (RK2)
The Mid-point method is a second-order Runge-Kutta method (RK2). Like Heun’s method, it uses a predictor-corrector framework to achieve a global accuracy of , which is superior to the accuracy of the standard Euler’s method.
Here is a breakdown of what is happening physically and mathematically in each step:
Step 1: The Mid-point Rule Approximation
We begin with the integral formulation of the step from to :
Instead of estimating the area under the slope function using the left boundary (yielding Euler’s method) or a trapezoid (yielding Heun’s method), we use the Mid-point rule of numerical integration. This rule assumes the average slope over the interval is best represented by the slope at the exact halfway point, :
Step 2: The Predictor (Half-Step Euler)
To evaluate the mid-point slope , we need the state value at the half-step. Since this value is unknown, we predict it.
We do this by taking a “half-step” of size forward from our current state using standard explicit Euler:
- is the slope at the start of the interval.
- Multiplying this slope by the half-step size and adding it to gives our trial prediction .
Step 3: The Corrector (The Final Update)
Once we have the predicted mid-point value , we can evaluate the derivative (slope) at this mid-point:
We then go back to the starting point and project forward across the entire interval of step-size using this newly calculated mid-point slope:
Summary of the Physics
Instead of blindly continuing along the initial slope for the entire duration of , the mid-point method “looks ahead” to the middle of the interval, calculates the slope there, and uses that mid-point slope to make a much more balanced and accurate step forward.
The Runge–Kutta 4th order method – Simpson’s rule
The RK4 method in four steps
- Compute
- Estimate the slope at using Euler’s explicit method:
- An improved estimate of the slope in step 2 is obtained by computing
- The slope at is estimated as
The RK4 method algorithm:
Give me additional commentary about the RK4 method and the steps shown here
ROBOT GENERATED – gemini-3.5-flash
The Classical Fourth-Order Runge-Kutta method (RK4) is the most widely used explicit numerical solver for initial value problems (IVPs). It achieves a high global accuracy of (meaning if you halve the step size , the global error decreases by a factor of ).
Here is a conceptual breakdown and additional commentary on the steps shown in your note:
1. Connection to Simpson’s Rule
The algebraic structure of RK4 is derived from Simpson’s rule for numerical integration. Simpson’s rule estimates the integral of a function over an interval by evaluating it at the start, midpoint, and end:
In the final RK4 algorithm formula, you can see this exact weighting:
- represents the slope at the start (weight: )
- and represent two different estimates of the slope at the midpoint. Together, they form the “4” in Simpson’s rule: (weight: )
- represents the slope at the end (weight: )
2. Deep Dive into the 4 Steps
Step 1: (The Trial Slope at the Start)
- What it is: The derivative (slope) evaluated at the beginning of the step, .
- Purpose: This is exactly what Euler’s method uses. It provides our initial direction.
Step 2: (First Midpoint Slope Predictor)
- What it is: An estimate of the slope at the midpoint .
- Purpose: Since we don’t know the exact value of at the midpoint, we “predict” it by taking a half-step of size using the starting slope . We then evaluate the derivative at this predicted midpoint state: .
Step 3: (Refined Midpoint Slope Corrector)
- What it is: A revised, more accurate estimate of the slope at the midpoint .
- Purpose: Instead of using the starting slope to predict the midpoint state, we use the newer, better midpoint slope estimate to project a new predicted midpoint state: . We then evaluate the derivative at this refined location.
Step 4: (The Endpoint Slope Predictor)
- What it is: An estimate of the slope at the end of the interval, .
- Purpose: We project all the way across the interval of size from using our refined midpoint slope . We then evaluate the derivative at this predicted end state: .
3. The Final Weighted Average
Once all four trial slopes are computed, the algorithm takes a weighted average of them:
Because the midpoint slopes ( and ) are generally more representative of the overall trajectory of the curve across the interval than the endpoints ( and ), they are given twice the weight. This final step yields an extremely stable and accurate step forward.
CAn you give me an example probelm with the solution for this method?
ROBOT GENERATED – gemini-3.5-flash
Here is a step-by-step example problem solved using the classical 4th Order Runge-Kutta (RK4) method.
The Problem
Using the RK4 method, approximate the solution to the following initial value problem (IVP) at using a single step of size :
Here, we have:
- Initial time and initial state
- Step size (so we want to compute )
Step-by-Step Solution
Step 1: Compute (Slope at the start)
Step 2: Compute (First midpoint estimate)
We evaluate the slope at the midpoint , predicting using :
Step 3: Compute (Refined midpoint estimate)
We evaluate the slope at the midpoint , predicting using the updated slope :
Step 4: Compute (Slope at the end)
We evaluate the slope at the end of the interval , predicting using :
Step 5: Calculate the final weighted average ()
Now, substitute the values of and into the RK4 algorithm based on Simpson’s rule:
Thus, the RK4 approximation at is .
Comparison with the Exact Solution
The exact analytical solution of this ODE (found using an integrating factor) is:
At :
The RK4 approximation () matches the true solution to six decimal places after only a single step (). This demonstrates the high-order accuracy of the classical method.